Large language models (LLMs) have become popular since 2023, such as GPT/Gemini/Tongyi Qianwen/GLM/Wenxin Yiyan/Doubao, etc. After more than a year of competition and evolution, they have almost covered all general and common sense knowledge and understanding;
At the same time, more companies in traditional industries are being drawn to the big language model ecosystem, exploring how new AI technologies can bring substantial transformation to their businesses. Unlike big model vendors, which compete on general capabilities, traditional companies are more focused on integrating the general capabilities of big models with specialized knowledge within their own industry or internal verticals to meet the needs of their unique business scenarios.
Vertical integration
Large language models integrate enterprise vertical domain knowledge in two main directions:
Fine-Tuning
Labeling private domain knowledge as training data and directly performing incremental training on the big model can improve the big model's own knowledge reserves and cognitive capabilities. This is also one of the ways for big model manufacturers to continuously improve model capabilities.
RAG(Retrieval Augmented Generation)
By building a retrieval system outside the big model, we can solve the problem of extracting and recalling the company's private domain knowledge, and use prompts to allow the big model to return results in the context of the company's private domain knowledge.
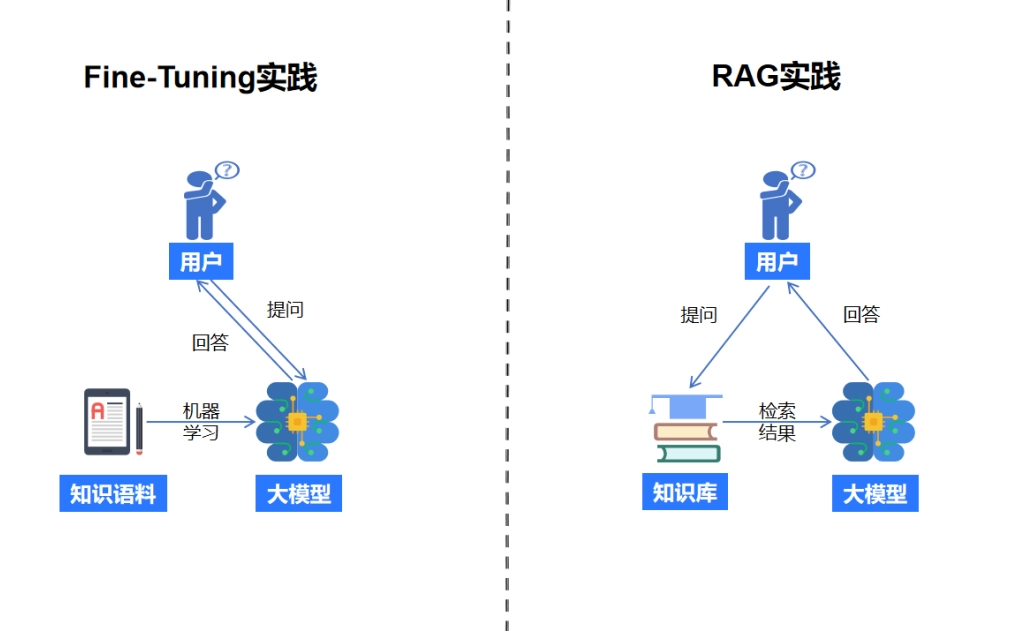
Unlike Fine-Tuning, RAG lowers the technical barrier to entry for enterprises applying large models, and has been a popular choice among non-AI companies since last year. This article draws on experience from multiple RAG implementation projects and explores how to better leverage the RAG framework to empower enterprises.
RAG's opportunities and pain points
The advantage of the RAG framework lies in the construction of a division of labor mechanism between query and generation, which enables the integration of enterprise private domain knowledge without requiring changes to the generation capabilities of the large language model.
Without the query stage, even though the input width of current large language models has exceeded one million tokens, it is still difficult to cover the entire private domain knowledge of an enterprise at once. Moreover, if every user query is accompanied by a large number of token prompts, it is also an extremely cost-effective method. Therefore, in the current computing power environment, RAG still plays a pivotal role in large model application scenarios.
Basic RAG framework diagram:
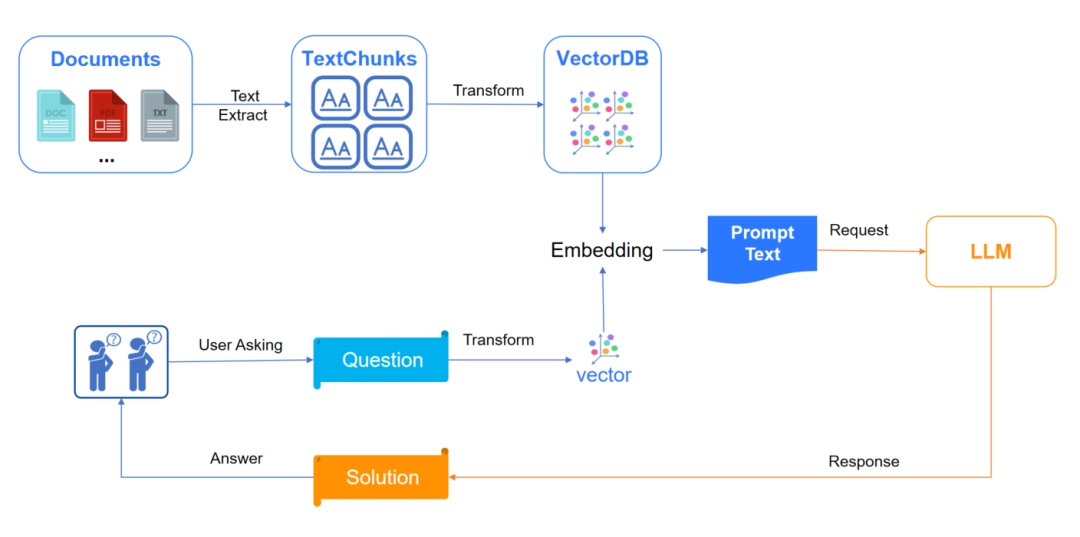
However, when enterprises implement large models and RAG frameworks, they sometimes find that certain situations are not satisfactory. Although the reasoning and generation capabilities of large models have matured, the query accuracy issues of the RAG framework's text fragment + vector recall mechanism often restrict the full potential of the large models. How to better coordinate the query and generation capabilities of the RAG framework has always been one of the exploration directions for large model applications.
RAG Optimization Practices
To address the pain points faced by RAG, we can summarize RAG's query system into three major steps: knowledge preprocessing, user questioning, and query recall. Within each step, we explore specific practices to help improve query issues:
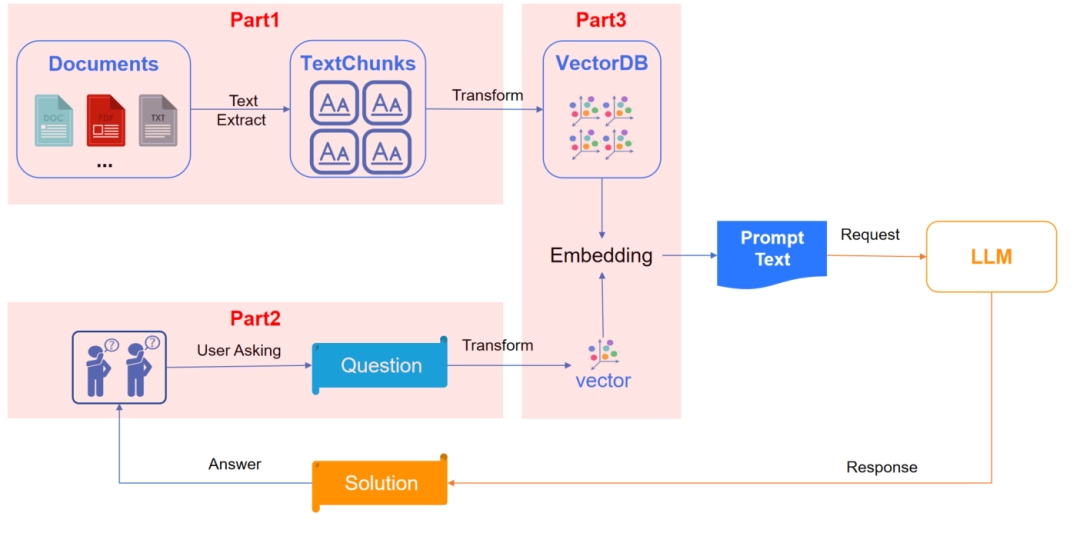
Part 1: Knowledge Preprocessing
RAG extracts knowledge content from various types of enterprise documents and breaks this content into knowledge blocks, which serve as the smallest unit of retrieval. The quality of the knowledge block directly affects the accuracy of subsequent retrieval and generated responses.
We can improve this link in two aspects:
1 Documentation Standards
Enterprises can standardize the content from the source of document writing and accumulation, so that it can be extracted and segmented more accurately by RAG. We provide several formats for reference:
Text: Use a paragraph structure with multi-level headings. The content under each last-level heading should not be too long (affected by the slice width). The content of each paragraph must be complete and clear.
Tables: Tables with single-row headers are best, and row data should avoid using merged cells.
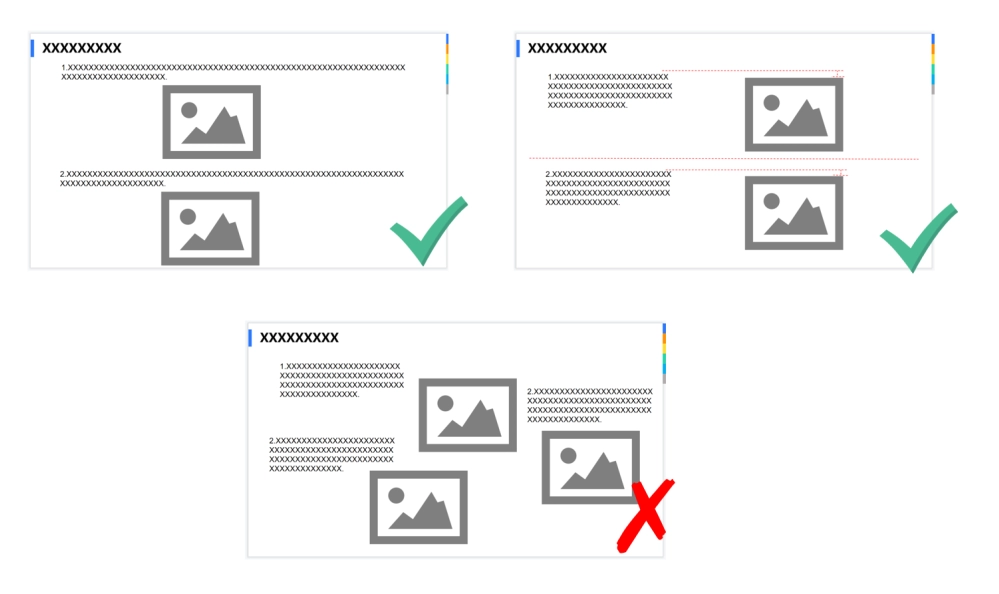
Pictures: The order of pictures and text should be clear. Generally, Word/PDF is suitable for a layout with text above and pictures below, while PPT can be suitable for a layout with text above and pictures below or text on the left and pictures on the right.
PDF: PDF is usually extracted using OCR, which is not sensitive to single line breaks. Therefore, it is recommended to use double line breaks to divide the text into paragraphs to facilitate paragraph identification.
Word content example

PPT content examples
2 Content Processing
For documents with low update frequency, we can use the large model Generate capability to intelligently process the document content. The specific implementation plan is as follows:
Smart summary: Extract a summary of the content of the entire document, which can be used to individually match user questions.
Question prediction: Predict questions for the entire document or document fragment, and generate multiple related question short sentences. The question short sentences can be used to individually match the user's questions.
Image processing: Relying solely on image context or ORC technology to infer the content of images is not reliable; we can use the large model's ability to understand images to summarize the images in the document into text descriptions, thereby matching them with user questions in the form of text.
Knowledge graph: With the help of large models, important entities in documents can be extracted more intelligently, and triples (entity 1 - relationship - entity 2) can be constructed to build a multi-document knowledge graph.
Part 2: User Questions
The content and method of user questions are also important factors affecting the accuracy of RAG. To improve this, we can add more explicit and implicit interactive links:
Clarification
Influenced by traditional text-recall search engines, many users are accustomed to asking questions with a single word or phrase, which leads to increased matching uncertainty. Leveraging large models, we can quickly construct a variety of clarification scenarios, assess and follow up on user questions, and summarize them into high-quality, complete questions for information retrieval.

Problems
The Generate feature of the large model can generate relevant information based on user questions, a process that is invisible to the user. These derived related questions can be used to retrieve more knowledge fragments, which are then sorted and merged into the prompt of the large model to ensure comprehensiveness of the generated response.
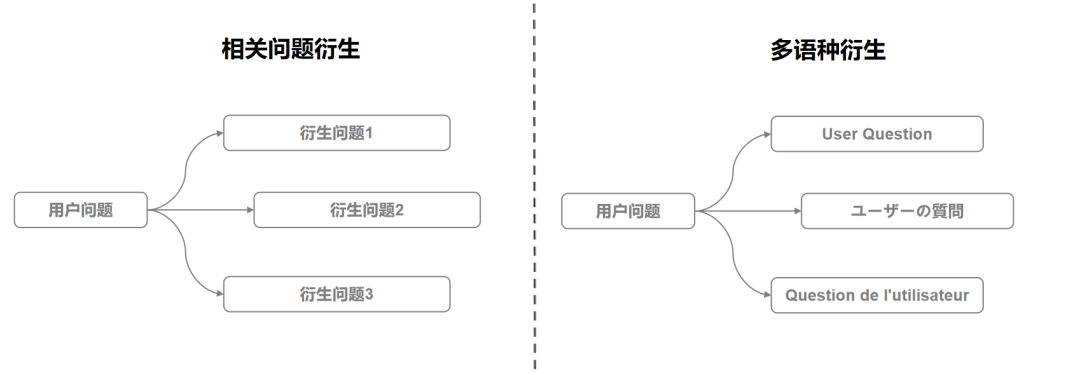
Question Classifier
Enterprises often have knowledge from multiple fields coexisting within them. When these knowledge points are retrieved together, they can often interfere with each other. By building a question classifier, different categories can be defined to point to different knowledge bases. Users can first clarify the question category when asking a question, or they can leverage the power of a large model to automatically classify questions. Combined with classification routing, this can avoid interference from similar knowledge from different fields.
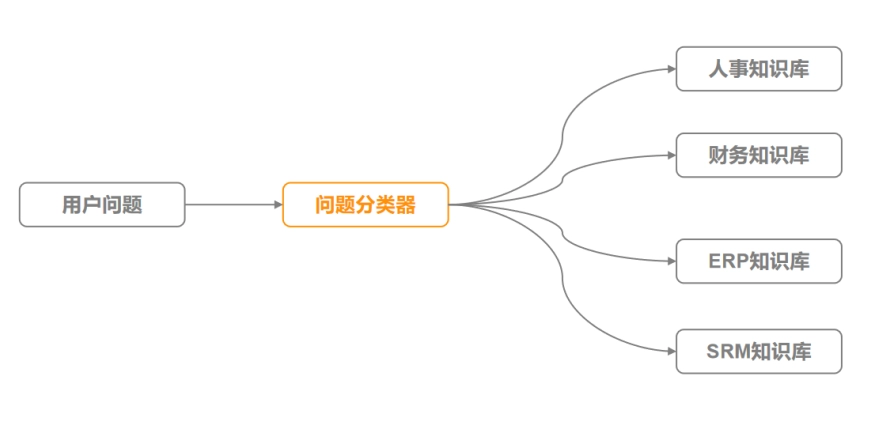
Part 3: Query Recall
This link bridges the gap between user needs and knowledge reserves and is a crucial component of the RAG framework, returning to the essence of query. Since humanity entered the information age, information search and recall have been an ongoing topic. We can also introduce excellent strategies and advanced technologies to improve recall accuracy:
Vector Model Recall
As the preferred choice of the RAG framework and the basic capability of query recall, when facing vector matching of long texts, we can choose a higher-dimensional vector model to capture and compare more feature values and improve accuracy.
Currently some vector models:
| Model | Dimensions |
| Bert vector model | 768 |
| BGE vector model | 1024 |
| GPT vector model | 1536~3072 |
Text vector combination recall
Text recall and vector recall are two common retrieval techniques for dealing with massive amounts of data, each with its own unique advantages and disadvantages. To improve retrieval performance, the two can be effectively integrated.
For example, we can first perform keyword-based text recall, and then implement vector recall based on this; or perform text matching and vector matching simultaneously, and finally use a comprehensive scoring model to sort and recall the results. Such a fusion strategy helps improve the accuracy and efficiency of retrieval.
Reranking Model Recall
The reranking model is a compromise between the low-computing, low-cost vector model and the high-accuracy, high-cost large language model. It combines the efficiency of the vector model with the semantic understanding capabilities of the large language model, aiming to provide better search results while reducing computing resource requirements.
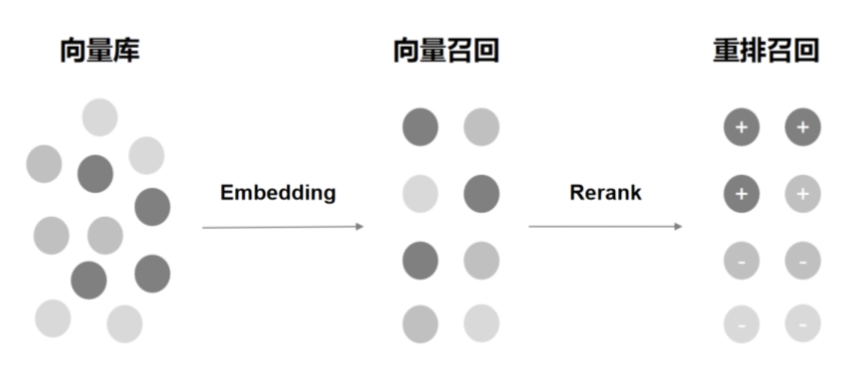
Reranking models such as the commercial closed-source Cohere Rerank model and the open-source bge-reranker-large model are currently popular reranking models.
Knowledge graph recall
Combined with the knowledge graph construction of document preprocessing, we can reference the graph's capabilities in the query recall phase, perform relational reasoning and graph query through entity recognition of the question; it can also be combined with text recall and vector recall to form a hybrid recall strategy to improve the overall search effect.
By standardizing internal enterprise systems, integrating large-scale model generation capabilities, and upgrading derivative technical tools, RAG is no longer simply a plug-in system for large-scale models, but rather a streamlined enterprise practice that deeply integrates a company's private domain knowledge with the general capabilities of large-scale models. In the future, with the continuous advancement of technology and the reshaping of user habits, RAG technology will also bring new opportunities and challenges to enterprises.
In today's AI era, we have fully entered the era of big models. The rapid development of big models and their derivative technologies are driving innovation and transformation across all industries. Technologies like RAG not only improve the efficiency of data processing and decision-making, but also open up endless possibilities for future application scenarios. From intelligent assistants to automated decision-making, from personalized recommendations to deep semantic understanding, future AI will be more intelligent, flexible, and humane. Looking ahead, we have reason to believe that with the continuous advancement of technology, AI will become more deeply integrated into our lives, changing the way we work and improving our quality of life.














![[A new domestic alternative to ServiceNow] Yan Qianyun makes a strong debut!](/uploads/upload/20250731/250I1141J3D3.webp)
